Step 5 - Getting Indexed

Introduction
Please don't fall for any offers advertising website submission services,
no matter how good they sound!
A search engine submission company offering to submit your website to 500,000
search engines. Very impressive!
In truth, there aren't even 500,000 search engines, but if you really
want to check for yourself you can visit search engine
colossus, They have a very extensive list of search engines from around
the world. The point we are making is Google, Yahoo!, and MSN are the
major players; spending any effort in trying to rank on the other engines
is simply not worth your time, unless your site has a local focus in a
specific country. In this case, it may be worth discovering other popular
local search engines and submit your site to them.
In the latest survey of the most popular search engines
conducted by Comscore, Google, Yahoo!, MSN and ASK
control over 90% of the search referrals in the United States and close
to that figure around the world. Google's dominance is even more impressive
in European countries such as the UK and Germany where Google's search
market share is nearly 75%.
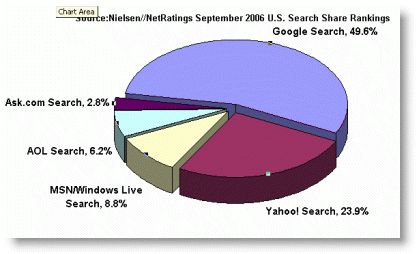
Recent survey results of the most popular search engines by Nielsen NetRatings.
Armed with these statistics, you should ask yourself, why on earth you
would want to submit your websites to the other 499,997 search engines?
In the last 5 years since Trendmx.com had been
online, we have yet to see a single visitor from one of those obscure
search engines these over hyped submission companies rave about.
How do websites get indexed?
If you have never submitted your website to any of the search engines
and found yourself stumbling upon your site on Google, Yahoo!, or MSN,
don't be overly surprised by your discovery, there is a good reason for
it.
The top three search engines have automated the retrieval of web content
by following hyperlinks from site to site. They are called "crawlers",
or sometimes referred to as "spiders", "bots" or "agents".
Their job is to index fresh updated content and links. Your website likely
got included in their database because the spiders have discovered a link
pointing to your new domain somewhere on the web. In short, someone had
placed a link pointing to your website on one of their web pages, blogs
or may be your site was bookmarked on popular bookmarking sites such as
Delicious.com or Stumbleupon.com.
Most likely nobody asked you for your permission to link to your site,
but alas, this is the nature of the web. Every website has the ability
to connect to another via hyperlinks.
Do I have to re-submit a new or changed web page to get re-indexed?
The crawler based search engines automatically re-index websites daily,
weekly or monthly depending on the website's popularity. The depth of
the indexing varies each time the search engines visit your website. Sometimes
they perform a deep crawl of every page and other times they may just
skim your website looking for changed or new web pages. The frequency
of the deep crawls can't be accurately predicted, but search engines perform
deep crawls about every 1-2 months and shallow crawls are performed as
often as daily, depending on how popular the website is and its Google
PageRank value. Higher Google PageRank triggers more frequent updates
by Google. We'll tell you more about the Google PageRank and its effects
on your search engine ranking in the next
lesson.
Submitting to international versions of Google, MSN and Yahoo! myth...
busted
Sometimes you may come across search engine submission companies making
wild claims about the advantages of their submission services. One of
those claims is the advantage of submitting to international versions
of Google, Yahoo!, and MSN. The offer goes something like this: "get
listed in Google UK, Germany, France, Brazil, etc." Sorry to be so
blunt here, but this is a load of "BS."
When you submit your website to Google, Yahoo!, or MSN, your website
is automatically included in all the international versions of their search
engines. The claim that you need to submit your site to international
versions of Google, Yahoo and MSN falls into the same category as submitting
your site to five hundred thousand search engines. In the end, it will
only make your wallet thinner and doesn't result in any advantage for
your site.
The traditional search engine submission process
Although the traditional method of submitting your website to a search
engine in order to get listed is still viable, there are much faster methods
to get your site indexed. The traditional registration method is known
as search engine submission and it's the process of directly notifying
the search engines about your new website by visiting them and submitting
your URL through their web forms.
In order to submit your website, you are required to enter your home
page URL only, and sometimes a brief description of your website. One
very important thing to note is you never
have to submit individual pages of your site to crawler based search engines.
Manual or automatic submission?
There are two ways you can submit your site to the search engines using
the manual method outlined above or using some type of automated software
tool or online service. Our own SEO software tool, SEO Studio comes with
a free automatic submission tool.
The most obvious benefit to using an automatic submission tool is that
it will save time. If you only want to submit one website to the Google,
Yahoo! and MSN you may be able to accomplish the task in less than an
a few minutes. But if you want to submit multiple websites to dozens of
international search engines the time required would be greatly increased.
The SEO Studio submission tool can submit your website details automatically
to multiple search engines simultaneously with the click of a button.
Optionally, the SEO Studio submission tool can create a submission report
for future record keeping.
How can we speed up the indexing process?
The average waiting period for a new website to get indexed by the major
search engines can vary from a few days to a month or more. If you get
impatient and decide to resubmit your site over and over again, the search
engines may in fact make you wait longer, so don't do it. The most effective
solution to getting your website indexed faster is to gain a few links
from sites that have already been indexed by Google, Yahoo! or MSN.
You may be able to reduce the waiting period for indexation from a few
weeks to as little as 48 hours by following these simple steps outlined
below:
Get your web
site listed in a local trade organization's online directory or
chamber of commerce website. Submit your web site
to international and local search engines and directories.
Exchange links
with other related websites, look for high Google PageRank link
partners. Get listed in
DMOZ, Yahoo! and other smaller, but high quality
directories. Create a useful
blog on topics related to your website, and ask other websites
to link to your blog. Submit your blog's
RSS feed to the top search engines. Google,
Yahoo! and MSN use blog feeds to power their blog search engines and when
you submit your blog's RSS feed URL, your site also gets indexed right
away. Participate in
popular forums or community discussions and post your website URL
as part of your signature. Create a press
release and submit it to an online press release distribution service
such as prweb.com Submit your site using
Delicious.com or Stumbleupon.com. Both of these social bookmarking and discovery
sites are an excellent way to get links pointing to your site. Submit your site using
the Google Site Map will
ensure a quick indexing process by Google of all your important web pages.
Finding cached copies of web pages
A cached copy of the web page is the search engine's view of a page
at a specific point in time in the past. Each cached web pages is time
stamped and stored for retrieval, but only the text portion of the page
is being saved by the search engines. All the images and other embedded
object are stripped out prior to archiving.
When the user clicks on a "Cached" web page link, the search
engines combine the archived HTML source code with the server side images
and object that are still present on the web server.

Clicking on the "Cached" link will retrieve the archived copy
of the web page as it was "seen" by Google the last time.
Yahoo! and MSN also provides
this very useful function to its users, but Google is the only one that
actually provides a command that you can enter in the search window to
look up a cached copy of a web page like this: cache:your-domain.com.
What are the page size limits for search engine crawlers?
An often neglected topic pertaining to search engine indexing is how
much content search engine spiders actually index. The search engine crawlers
have preset limits on the volume of text they are able to index per page.
This is important, because going over the page size limit could mean your
pages may only be partially searchable.
Each search engine has its own specific page size limits. Familiarizing
yourself with these limits can minimize future indexing and ranking problems.
If a web page is too large, the search engines may not index the entire
page. Although the search engines don't publish exact limits of their
spiders' technical configuration, in many instances we can draw definite
conclusions about page size limitations. Various postings by Gooogleguy, on Webmasterwold.com and our own observations
point to a 101 Kilobytes (KB)
text limit size by the Googlebot crawler. At the beginning of 2005 it
appeared that Google indexed more than 101 Kilobytes of individual HTML
pages. We continue to see evidence of web pages larger than 101KB in the
search results pages of Google.
Here is an example of a large HTML page found on Google with a search
for the keyword "recipe" Try typing this command into the Google
search box: filetype:html
recipe. The screenshot below shows a web page, indexed with over 200
Kilobytes of text.
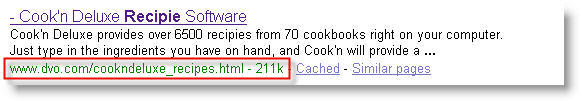
The evidence of larger than 101KB HTML documents being indexed by Google
in July 2005
Other popular document types found on Google are Adobe's Portable Document
File (PDF) types. The PDF file size indexed by Google is well over the
101 Kilobytes allowed for HTML document types; we estimate the file size
limit for PDF files to be around 2 Megabytes.
The other major search engines, Yahoo! and MSN have similar or even
higher HTML, and PDF file size limits. For example the Yahoo! and MSN
spider's page size limit seems to be around 500 Kilobytes. Beyond the
well known PDF file format, all major search engines can index flash,
Microsoft Word, Excel, PowerPoint, and RTF rich text file formats.
Checking your website's indexed pages manually
In the previous section we have discussed how new websites get indexed
and how the submission process works. If we want our websites to rank
well, we have to make sure all the web pages contained within our website
get crawled as frequently as possible.
Finding out how many web pages the search engines have indexed is important
for two reasons:
Web pages that are
not indexed by the search engines can never achieve any ranking. In order to determine a web page's relevance
in response to a query, the search engines must have a record of that
page in their database including the complete page content. The number of
web pages indexed can influence a website’s overall ranking score. Larger
websites tend to outrank 2-3 page mini websites, providing all other external
ranking factors are equal. A word of caution to those who are thinking
of using automated tools to produce thousands of useless pages to increase
a website's size. This type of "scrapped" content will only
ensure your site will be banned by the engines in no time.
There are very simple ways to check if your website has already been
indexed. Go to a search engine, and simply enter the domain name of your
website or some unique text that can be found on your web page only. This
can be your business name or a product name which is unique to your website.
Finding out if your home page is indexed is very important, but what
about all the other pages on your site? Google, Yahoo!, and MSN provide
search commands for finding all the pages indexed on a specific domain.
These search options are accessible on most engines by clicking on the
advanced search option link next to the search box.
Here is a list of commands for the major search engine to find the individual
web pages indexed:
Total indexed pages online reporting tools
The above method for checking indexed pages is just one of many ways
we can find out how many pages got indexed by the search engine crawlers.
There are some excellent free online tools available to check the number
of indexed pages on multiple search engines simultaneously. We are especially
fond of Marketleap.com's indexed page checking feature.
Their search
engine saturation reporting tool is especially useful since it allows
you to enter up to 5 other domain names to check. This a great way to
check side-by-side the number of web pages indexed compared to your competitors.
Detailed indexed pages reporting with SEO Studio
SEO Studio provides an indexed page checking feature as part of the
Links Plus+ tool. The Links Plus+ tool can extract
additional information about each indexed URL, including the page title,
META keywords, META descriptions and Google PageRank. If you enable the
keyword analysis option in the advanced options screen, Links Plus+ can
also display the keyword density of the title and META tags for each individual
page.
One of the most valuable features of this tool is its ability to display
the Google PageRank of each indexed page. The Google PageRank is an important
ranking factor, and a good indication how well individual pages can compete
for top rankings.
In the next lesson, we will cover a topic called “deep linking” and
how individual pages on your website can rank higher for specific keyword
terms than your home page for example. When you know the PageRank value
of individual pages on your website, you can better target your link popularity
campaign to channel PageRank to individual pages and to increase the number
of pages indexed by the search engines.
Controlling search engine spiders with the Robots.txt file
The major search engines including Google, Yahoo! and MSN use web crawlers
to collect information from your websites. These search engine spiders
can be instructed to index specific directories or document types from
your website with the use of the robots.txt file. This file is a simple
text file and has to be placed in the root folder or top-level directory
of your website like this: www.mydomain.com/robots.txt.
The robots.txt file can contain specific instructions to block crawlers
from indexing entire folders or document types, such as Microsoft Word
or PDF file formats.
The Robots.txt file has the following
format:
User-agent: <User Agent Name or use "*" for all agents>
Disallow: <website folder or file name or use "/" for
all files and folders>
In the table below we have provided some instructions on how you can
set different crawler blocking methods in the robots.txt file.
|
To
do this: |
Add
this to the Robots.txt file: |
|
Allow all robots full access
and to prevent "file not found: robots.txt" errors |
Create an empty robots.txt
file |
|
Allow all robots complete
access |
User-agent: *
Disallow: |
|
Allow only the Googlebot spider
access |
User-agent: googlebot
Disallow:
User-agent: *
Disallow: / |
|
Exclude all robots from the
entire server |
User-agent: *
Disallow: / |
|
Exclude all robots from the
cgi-bin and images directory |
User-agent: *
Disallow: /cgi-bin/
Disallow: /images/ |
|
Exclude the Msnbot spider
from indexing the myonlinestore.html web page |
User-agent: Msnbot
Disallow: myonlinestore.html |
Controlling indexing of individual web pages with META tags
One of the simplest ways to control what search engines index on your
website is to insert code inside your HTML pages META tags section. You
can insert robots META tags that can restrict access to a specific web
page or prevent search engine spiders from following text or image links
on a web page. The main part of the robot META tag is the index
and follow instructions.
The robots
META tag has the following format:
INDEX,FOLLOW: <Index the page and follow links>
NOINDEX,NOFOLLOW: <Don't Index the page and don't follow links>
The example below displays how we can use the robots META tag to prevent
spiders from indexing or following links on this web page.
|
<HTML>
<HEAD>
<META NAME="ROBOTS" CONTENT="NOINDEX,NOFOLLOW">
</HEAD>
<BODY> |
In the table below we have provided some more examples of how the robots
META tags can be used to block search engine crawlers from indexing web
pages and following links.
|
To
do this: |
Add
this to HEAD section of your web pages: |
|
Allow the web page to be indexed
and allow crawlers to follow links |
<META NAME="ROBOTS"
CONTENT="INDEX,FOLLOW"> |
|
Don't allow the web page to
be indexed and allow crawlers to follow links |
<META NAME="ROBOTS"
CONTENT="NOINDEX,FOLLOW"> |
|
Allow the web page to be indexed,
but don't allow crawlers to follow links |
<META NAME="ROBOTS"
CONTENT="INDEX,NOFOLLOW"> |
|
Don't allow caching of the
web page |
<META NAME="ROBOTS"
CONTENT="NOARCHIVE"> |
|
Don't allow the web page to
be indexed and don't allow crawlers to follow links |
<META NAME="ROBOTS"
CONTENT="NOINDEX,NOFOLLOW"> |
Indexed pages reporting tools using web server logs
So far we have discussed the methods you can use to find out which pages
on your site had been indexed by the search engines. An alternative and
very effective method to report search engine spider activity on your
website is to use your web server logs and some type of visitor analysis
software that can extract search engine crawler data.
Each time a search engine spider requests and downloads a web page,
it creates a record in the web server's log file. Analyzing these large
web server logs can not be accomplished effectively without the use of
specific software tools. These tools can aggregate and summarize large
amounts web server log data and report search engine spider activity by
page. Some of the better known visitor statistics analysis tools can provide
basic search engine spider reporting, but a specialized software tool
called Robot-Manager Professional Edition can also
help you create Robots.txt files.
When analyzing web server logs we want to know:
Have there been any
search engine spider visits? If there
are no spider visits, there is no chance of getting ranked. If you don't
see any sign of crawler activity in your web server logs it's time to
get your site indexed by acquiring some high quality links. Please refer
to our guide on Getting Indexed in step 5. When was the last spider
visit? The more recent the last crawler
visits are the better. Frequent search engine bot visits ensure your new
and updated content gets into the search engine databases and can potentially
rank in the search results. Did all the major search
engine spiders send their crawlers to index our website? Google,
Yahoo! and MSN all have their own crawler agents and they leave different
trails in the web server logs to identify them. Please refer to the list
below to identify the Google, Yahoo! and MSN crawlers.
Googlebot: Mozilla/5.0
(compatible; Googlebot/2.1; +http://www.google.com/bot.html), Yahoo! Slurp:Mozilla/5.0
(compatible; Yahoo! Slurp; http://help.yahoo.com/help/us/ysearch/slurp) and the MSNbot:msnbot/1.0
(+http://search.msn.com/msnbot.htm) Did the search engine
spiders index all of our web pages? We
can type the URL into the search engine's search box, we can use the site
command, and we can also check the spidered pages using a web server log
analyzer. Did the search engine
spiders yield to our Robots.txt file exclusion instructions? Finding
web pages or images that you don't want the public to see on the search
engines can be very upsetting. You should double check your robots.txt
file instructions and perform a search for restricted file URLs and images
on the search engines.
Indexed pages reporting tools using server-side scripts
If you don't want to download large amounts of web server log files
to analyze, there is another method to report search engine spider visits.
A free set of web server scripts called SpyderTrax
was developed in PERL by Darrin Ward to track some of the major search
engines spiders, Google, Yahoo!, MSN, AltaVista, AllTheWeb, and Inktomi
among others. Complete installation instructions are available on the
website. Once you have inserted a few lines of code into your web pages,
the program starts tracking spider visits automatically.
The screenshot below illustrates how SpyderTrax reports search engine
spider visits.

SpyderTrax's search engine crawler activity reporting interface
Conclusion
The crawler based search engines make
the webmasters job really easy. Initially, you have to let the search
engines know your site is online by giving them a link to follow or submit
your home page directly. Without any additional work on your part, your
site will be visited over and over again by the search engine robots to
find any new pages or updated content. The search engines give us the
tools to find out which individual pages are in their databases. We also
have a great amount of control what parts of our website we want them
to index with the use of the robots file and META tags on individual web
pages.
|



